Öfters zeige ich Euch meine Wettkampfdaten, vor allem meinen Personal-Best-Graphen mit dem Steffny-Riegel-Modell drin. Einige von Euch haben nun gerechnet und verglichen, zwei Ergebnisse sind mir bekannt – das von Martin und das von meiner Laufpartnerin Stephanie. Da ich ein wenig überrascht davon war, wie viel Interesse an meinem Fit des Modells bestand, stelle ich Euch nun eine hoffentlich halbwegs benutzbare Version meiner Datei zur Verfügung.
Damit Ihr mit den Einstellungen spielen könnt, habe ich die (ja ohnehin mehr oder minder in Ergebnislisten öffentlichen) Daten meiner Wettkämpfe drin gelassen. Diese könnt Ihr natürlich nach Belieben raus löschen und durch Eure eigenen ersetzen. Alles, was man für den Normalbetrieb nicht ändern muss, ist als gesperrte Zelle auf gesperrten Tabellenblättern realisiert und ggf. auch gar nicht auswählbar. Die Seiten sind allesamt ohne Passwort gesperrt, so dass Ihr sie in Excel einfach entsperren und dann nachgucken könnt, wie das Ganze funktioniert.
Wichtig: Ich habe kein „Abfangen“ für unvollständig eingetragene Wettkämpfe auf dem Tabellenblatt ganz links gebaut. Wenn Ihr also nur eine Distanz, aber keine Zeit in einer Wettkampfzeile eintragt, ergeben sich eventuell Fehler. Das will ich irgendwann noch abfangen, habe ich aber nicht.
Im zweiten Tabellenblatt könnt Ihr erstens eingeben, nach welchem Datum Eure Wettkämpfe als „aktuell“ hinterlegt werden. Einen Einfluss auf das angefittete Modell hat das nicht. Zweitens könnt Ihr dort in einer Spalte, in der im Moment nur „Ja“s untereinander stehen, diese „Ja“ durch „Nein“ ersetzen. Dann wird das entsprechende Personal Best nicht in der Regressionsgerade genutzt. Das bietet sich zum Beispiel an, wenn Ihr wisst, dass Euer Fünfer oder Euer Marathon besonders schlecht oder gut sind, und Ihr wissen wollt, wie der Fit ohne diese außergewöhnliche Leistung aussieht.
Bei Fragen und Fehlern gerne hier in die Kommentare schreiben. Ich hoffe, es ergeben sich aus der zur Verfügung gestellten Datei mehr Antworten für Euch als Fragen oder Fehler.
Seit geraumer Weile führe ich nicht nur über mein Training, meine Krankheiten und einiges mehr Buch, sondern auch über meine Wettkämpfe. Neben der Wettkampfseite der Highway Tales gibt es auch noch meine Wettkampfdatei. Da ich diese nur selten pflegen muss, nämlich immer nur dann, wenn ich einen Wettkampf gelaufen bin, habe ich sie separat geführt. Natürlich wäre es cool, Wettkämpfe aus dem Trainingstagebuch zu extrahieren und auszuwerten. Das würde aber ein paar zusätzliche Felder bedingen, die für das alltägliche Training sinnlos sind und grundlos Platz verbrauchen. Daher die separate Datei.
So sieht die Dateneingabe aus. Was grau hinterlegt ist, kann nicht geändert werden (ich habe die Zellen gesperrt und das Blatt geschützt). Ich gebe die Wettkampfdistanz ein, die Zeit, in der ich sie absolviert habe, den dabei überwundenen Anstieg in Höhenmetern und den mittleren Puls über den Wettkampf. Dazu noch ein paar Daten zur Platzierung, das Datum und der Name des Wettkampfes. Daraus werden die Pace in Zeit, die Pace in Minuten pro Kilometer mein Formschätzer PRAPP berechnet. Außerdem gibt es noch ein Feld, in dem für als „aktuell“ definierte Wettkämpfe die Pace steht und für andere der Fehlercode „#NV“. Das Datum, nach dem ein Wettkampf als aktuell gilt, kann ich einstellen.
Die 10-km-Äquivalenz-Pace ist schon ein abgeleiteter Wert. Dabei benutze ich eine Best-Fit-Kurve an meine Personal Bests, um die Leistung auf eine 10-km-Pace zu „normieren“. Mit diesem Wert kann ich dann eine Zeitleiste erstellen, in der alle meine Wettkämpfe über die Zeit hinweg mit einem „neutralisierten“ Tempo betrachtet werden, so dass Marathon und Vier-Kilometer-Lauf (näherungsweise) vergleichbar werden, in dem man sie auf 10 km umrechnet.
Klingt komisch, ich weiß. Aber es funktioniert. Dafür benutze ich die Formel nach Steffny und Riegel. Eine andere Erklärung zum Thema findet man hier. Was behauptet diese Formel nun? Ganz einfach – sie geht davon aus, dass man mit der Streckenlänge langsamer wird. So weit, so Binse. Das Modell sagt nun, dass dieses langsamer Werden als Ermüdungskoeffizient dargestellt werden kann. In Worten: Die bestmöglichen Wettkampfzeiten verhalten sich wie die Wettkampfdistanzen potenziert mit dem Ermüdungskoeffizienten. Also zum Beispiel
Der Clou daran ist, dass beim Betrachten von Weltbestzeiten (auch und insbesondere Altersklassen-Weltbestzeiten, beide Geschlechter) für die Autoren des Modells der Schluss nahe lag, dass dieser Ermüdungskoeffizient konstant bei ungefähr 1,07 liegt. Das wollte ich für mich selbst genauer wissen – denn vielleicht habe ich ja ein Talent für die Langstrecke – oder eines für die Kurzstrecke. Ich habe die Formel etwas griffiger für mich in „Pace“, also das Läufertempo umgerechnet. Dafür teilt man einfach das obige durch Strecke1 / Strecke2.
Der Exponent sollte also 0,07 sein, wenn Steffny, Riegel (und Greif war glaub‘ ich auch mit von der Partie) recht haben sollten. Ich rechnete den ganzen Kram also nochmal um, um ihn an meine persönlichen Bestzeiten anzupassen, und nahm als Referenzwettkampfstrecke den „Einer“, also den LC1000 nach der Laufcampus-Methode. Wer will, kann als Referenz den Fünfer, den Zehner oder die „Magic Mile“ nehmen, es bleibt sich gleich. Im Endeffekt steht dann (bei mir) da:
Pace(Strecke) = 1RT * (Strecke / 1 km)Ermüdung-1
Diese Formel kann ich auf alle meine Wettkampfpaces anwenden und bekomme ein Ein-Kilometer-Renntempo (1RT) und einen Exponenten Ermüdung-1 als Fitergebnisse. Das geht einerseits numerisch, wenn ich es logarithmiere, kann ich aber sogar lineare Regression mit analytischer Lösung drauf anwenden – das hat den Vorteil, dass ich beim Eintragen eines neuen Personal Best nicht manuell den numerischen Fit anwerfen muss, sondern meine Steffny-Riegel-Kurve automatisch aktualisiert werden kann. Und so sieht das dann aus:
Im obigen Diagramm steht jeder blaue Punkt für eine Wettkampfleistung von mir, jeder grün hinterlegte Punkt für eine meiner Wettkampfleistungen seit dem 01.10.2023 und jede rot umrandete, blaue Raute für eine persönliche Bestleistung. Marathon-, Fünfer- und Fünfzehner-PB sind also aktuell. Die gelbe Kurve ist die Steffny-Riegel-Funktion angepasst an meine persönlichen Bestleistungen (rotgeränderte Rauten), also meine ganz persönliche Ermüdungskurve. Sie suggeriert ein 1RT von 3:22, also dass mein schnellster Kilometer in 3:22 gelaufen wäre. Das kommt in etwa hin, wenn ich gut drauf bin – 3:17 habe ich schonmal geschafft, meistens dümpele ich irgendwo um die 3:25, wenn ich normal drauf bin. Der Exponent ist 0,0685, also sogar etwas flacher als bei der Kurve, die die Sportwissenschaftler und Trainer von den Weltbestleistungen abgeleitet haben. Das liegt natürlich auch am grandiosen Marathon dieses Jahr, vor den 3:06:06 in Kandel lag der Exponent noch eher im Bereich von 0,075, ich hatte also einen stärkeren Ermüdungskoeffizienten als das Modell.
Mit dem 1RT setze ich auch regelmäßig über einen „LC1000“ meine Wettkampftempi neu, ich experimentiere gerade mit einer Neubestimmung in jeder vierten Woche. Mit der Formel 1RT mal Distanz in Kilometern hoch Ermüdungskoeffizient bestimmte ich dann 5RT, 10RT, HMRT und MRT, und damit meine Intervall- und Wiederholungstempi und meine Wettkampfprognosen. Da ich aber dem Frieden noch nicht traue, gehe ich immer noch eher konservativ von einem Ermüdungskoeffizenten von 0,08 (bzw. in der Formulierung von Steffny und Riegel 1,08) aus, um meine Wettkampfprognosen in leichtem Understatement zu halten, damit der Druck von selbst auf selbst nicht zu hoch wird. Mit der gelben Kurve rechne ich dann auch das Zeitleistendiagramm auf 10-km-Pace um, da nutze ich aber das Ergebnis des Fits.
Der momentane Wert von 0,0685 bzw. 1,0685 für den Ermüdungskoeffizienten weist mich als eher langstreckenaffin aus.
Ich hoffe, Martin, der sich eine Erklärung hierzu auf Strava gewünscht hat, kann mit dieser Erklärung etwas anfangen.
Mein Großvater war großer Perry-Rhodan-Fan. Das merke ich rückblickend auch daran, dass viele der Geschichten, die er mir „ad hoc“ auf von mir als Kind ihm zugekrähte Szenarien kreativ erzählte – immer wieder transferierte er dafür Themen, Figuren und Geschichten-Strukturen, die ich inzwischen aus Perry Rhodan kenne, in das von mir vorgegebene Detektiv- oder Fantasy-Szenario. Bei Weltraum-Szenarien, die auch häufig vorkommen, musste er weniger transferieren. Ich weiß inzwischen auch aus Erzählungen, nicht zuletzt von ihm selbst, als ich etwas älter war, dass er Perry Rhodan gelesen hat. Der kreative Umgang mit dem Geschichtenschatz, den er aus den Heften der längstlaufenden Science-Fiction-Heftreihe der Welt und seinem Improvisationstalent aufbaute, hat mich tief beeinflusst.
Inzwischen erkenne ich immer wieder Elemente, die in Geschichten meines Opas vorkamen, die andere Szenarien bedienten und mich oder mein Alter Ego zum Zentrum hatten, wenn mir mein „lebendiges, geliebtes Hörbuch“ Perry Rhodan vorliest. Mein „Ehewolf“ Holger hat irgendwann angefangen, mir vorzulesen, wenn ich in der Badewanne lag, inzwischen liest er mir immer vor, wenn ich koche – und zur Zeit sind das die Silberbände von Perry Rhodan. Wir stehen da mittlerweile am Ende des Aphilie-Zyklus‘, und ich weiß, das ist noch unglaublich weit von den gegenwärtigen Heften entfernt.
Aus Perry Rhodan kenne ich nun eben die außerirdische „Rasse“ bzw. das Volk der Kelosker. Diese waren Mitglieder des Konzils der Sieben, eines imperialistischen Bündnisses, das ganze Galaxien unterjochte. Allerdings waren sie die Nerds, die Rechner, die abstrakten Strategie-Berechner, denen teils gar nicht klar war, was sie da genau mit ihrem enormen, in Zahlen gefassten Verständnis vom Universum, dem Leben und dem ganzen Rest unterstützten. Ganz ähnlich war’s ja mit den Greikos, die vom imperialistischen Aspekt ferngehalten waren und mit ihrer Ausstrahlung den emotionalen Zusammenhalt des Konzils gewährleisteten, wenn die Eroberungen schon gemacht waren. Aber ich war bei den Keloskern, und das hat einen Grund. Die Kelosker sind plumpe Geschöpfe, die aber sehr viel wahrnehmen, auch multidimensional wahrnehmen, in Zahlen fassen und – freilich in den Büchern nicht so genannt – dann mathematisch modellieren, im Prinzip live nicht nur lineare Trends anfitten, wie das das menschliche Gehirn tut, sondern eben weiter gehen, vieldimensionale, vielparametrige, nicht-lineare Modelle auf die als Zahlen wahrgenommene Realität anwenden, sie anpassen und als Prognose- und Handlungsempfehlungswerkzeug verwenden. Für den expansionistischen Rest des Konzils natürlich eine Eigenschaft, die sich hervorragend nutzen lässt, um langfristig überlegen zu planen.
Und so fühle ich mich manchmal, wenn ich die Welt in Zahlen, in als mathematische Funktionen gefassten Modellen erfasse, Modelle anpasse und das in Diagrammen darstelle, quasi wie eine Keloskerin unter den anderen Völkern. Klar, auch ich poste in den sozialen Medien und hier auf dem Blog sowas wie mein „Angeberbild“ vom Badenmarathon oder unterfüttere Erlebnisse mit (wenigen) Bildern von mir, der Landschaft oder anderen. Aber wenn ich mir zum Beispiel in die Mediathek der verwendeten Bilder der Highway Tales schaue, sind da weit mehr Diagramme als Fotos. Als Linien und Punkte gefasste Zahlen, eingeordnet zwischen Koordinatenachsen, unterschieden durch Farben und Markierungen, erläutert durch „Legenden“, also eine Beschriftung, welche Farbe für welchen Datensatz oder welches Modell steht. In welcher Hinsicht ich nun gegebenenfalls keloskerhaft plump bin, weiß ich nicht – in Sachen gymnastische Bewegung wahrscheinlich schon, aber langsam und träge zu Fuß wie eine Keloskerin bin ich nun nicht. Dennoch bin ich ein Nerd, arbeite mit Zahlen und Modellen und Diagrammen. Emotionsfrei bin ich nicht, alles andere als das. Schlechtes, Demotivierendes kann mich furchtbar runterziehen, Tolles unglaublich euphorisieren. Es ist auch nicht so, dass ich meinen Sport nur nach Zahlen betreibe – das Gefühl spielt eine große Rolle. Aber vieles erfasse ich in Zahlen, versuche, es in Modellen zu parametrisieren, Trends aufzuzeigen, Kenngrößen zu definieren und zu verfolgen.
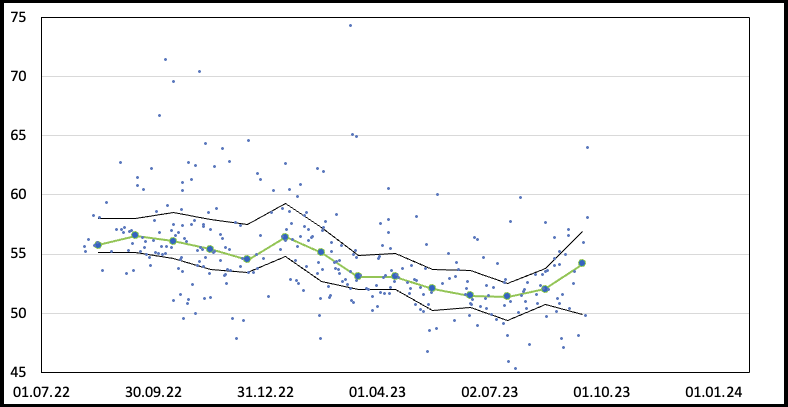
Und ich werde – gefühlt – besser darin. Nachdem ich mir das PRAPP auf Höhenmeter zu rechnen begonnen habe, habe ich diesen Wert nun auch auf meine Läufe angewandt. Da ich ja immer noch ein bisschen mit Bildern im Hintergrund arbeite, habe ich… nun, einen Graphen etwas aufgehübscht:
Im unteren, neuen Bild sieht man, dass tatsächlich auf Regensburg hin meine Formkurve anstieg, also das sbPRAPP im Mittel absank. Die grüne Linie mit blauen Markern stellt den Median des sbPRAPP im jeweiligen Monat dar, die schwarzen Linien 25- bzw. 75-Perzentile und die einzelnen Punkte sind die einzelnen Läufe. Offenbar hat meine Form nach Regensburg nochmal ordentlich zugelegt, nun beim abrufen von Leistung steigt der Wert an. Aber das ist bei harten Wettkämpfen nicht unnormal. Mal sehen, wie es sich weiter entwickelt.
Der Berg im Hintergrund des Graphen zur „Flachheit“ des sbPRAPP gegenüber den Höhenmetern ist übrigens der Nanga Parbat.
Weil ich so begeistert davon war, dass ich ohne numerischen Fit auskam, und so meine sbPRAPP-Funktion über eine analytische Lösung für eine Ausgleichsgerade automatisch angepasst wird, wenn neue Daten dazu kommen, habe ich für meine Wettkämpfe etwas Ähnliches gebaut.
In diesem Plot sieht man alle meine Wettkämpfe – die Distanz wird (logarithmisch) nach rechts aufgetragen, die „Pace“, also das Tempo in Minuten pro Kilometer nach oben. Blaue Punkte sind Wettkampfleistungen, die ich irgendwann gebracht habe, rot umrandete Rauten persönliche Bestleistungen auf der jeweiligen Distanz, grün hinterlegte Punkte oder Rauten sind „aktuell“, was im Moment bedeutet, dass die Leistungen nach dem 01.11.2022 erbracht wurden. Die rote Kurve ist ein numerischer Parabel-Fit an die Personal Bests, die gelbe Kurve ein Potenzgesetz nach Steffny und Riegel, basierend auf einer von Riegel 1977 aufgebrachten Formel. Demnach verhalten sich die Wettkampf-Zielzeiten zueinander wie die Wettkampfdistanzen hoch 1,07. Daraus folgt auch, dass sich das Renntempo wie die Wettkampfdistanz hoch 0,07 verhält… aber vielleicht ist ja der Exponent bei mir nicht 0,07, sondern 0,06, weil ich besonders gut auf langen Distanzen bin, oder 0,08, weil die ganz langen Distanzen mir bisher Probleme machen – Ihr ahnt es schon, es ist eher 0,08. Da steht dann also eine Funktion:
Wettkampftempo (x km) = Wettkampftempo (1 km) mal x hoch Exponent
Wenn ich das logarithmiere, ist es eine Gerade – und da kann man dann eine Ausgleichsgerade durchlegen, wofür es eine analytische Lösung gibt. Der Vorzug ist, dass sich bei neuen Personal Bests das Ganze automatisch aktualisiert. Wenn ich mich also irgendwann von der Parabel trennen kann, wird auch hier der Solver von Excel überflüssig, und somit aktualisiert sich meine ganz eigene Personal-Best-Funktion auf der Basis des Steffny-Riegel-Modells automatisch, wenn ich neue Personal Bests eingebe.
Dafür muss ich dann entweder endlich mein Potential im Marathon wirklich ausschöpfen – oder einsehen, dass ich bei der Parabel zwar eine schön kleine Summe der quadratischen Abweichungen erhalte, aber in erster Linie eben deswegen, weil ich „überfitte“, also nicht in der Natur der Sache, sondern in Schwankungen oder mangelnden Versuchen im Marathon liegende Strukturen mit in die Funktion nehme, was ich eigentlich nicht will.
Und dann brauche ich den Solver nicht mehr. Rede ich nun wie ein in die siebte Dimension sehendes Alien, das die Welt in Zahlen wahrnimmt?