Mein Großvater war großer Perry-Rhodan-Fan. Das merke ich rückblickend auch daran, dass viele der Geschichten, die er mir „ad hoc“ auf von mir als Kind ihm zugekrähte Szenarien kreativ erzählte – immer wieder transferierte er dafür Themen, Figuren und Geschichten-Strukturen, die ich inzwischen aus Perry Rhodan kenne, in das von mir vorgegebene Detektiv- oder Fantasy-Szenario. Bei Weltraum-Szenarien, die auch häufig vorkommen, musste er weniger transferieren. Ich weiß inzwischen auch aus Erzählungen, nicht zuletzt von ihm selbst, als ich etwas älter war, dass er Perry Rhodan gelesen hat. Der kreative Umgang mit dem Geschichtenschatz, den er aus den Heften der längstlaufenden Science-Fiction-Heftreihe der Welt und seinem Improvisationstalent aufbaute, hat mich tief beeinflusst.
Inzwischen erkenne ich immer wieder Elemente, die in Geschichten meines Opas vorkamen, die andere Szenarien bedienten und mich oder mein Alter Ego zum Zentrum hatten, wenn mir mein „lebendiges, geliebtes Hörbuch“ Perry Rhodan vorliest. Mein „Ehewolf“ Holger hat irgendwann angefangen, mir vorzulesen, wenn ich in der Badewanne lag, inzwischen liest er mir immer vor, wenn ich koche – und zur Zeit sind das die Silberbände von Perry Rhodan. Wir stehen da mittlerweile am Ende des Aphilie-Zyklus‘, und ich weiß, das ist noch unglaublich weit von den gegenwärtigen Heften entfernt.
Aus Perry Rhodan kenne ich nun eben die außerirdische „Rasse“ bzw. das Volk der Kelosker. Diese waren Mitglieder des Konzils der Sieben, eines imperialistischen Bündnisses, das ganze Galaxien unterjochte. Allerdings waren sie die Nerds, die Rechner, die abstrakten Strategie-Berechner, denen teils gar nicht klar war, was sie da genau mit ihrem enormen, in Zahlen gefassten Verständnis vom Universum, dem Leben und dem ganzen Rest unterstützten. Ganz ähnlich war’s ja mit den Greikos, die vom imperialistischen Aspekt ferngehalten waren und mit ihrer Ausstrahlung den emotionalen Zusammenhalt des Konzils gewährleisteten, wenn die Eroberungen schon gemacht waren. Aber ich war bei den Keloskern, und das hat einen Grund. Die Kelosker sind plumpe Geschöpfe, die aber sehr viel wahrnehmen, auch multidimensional wahrnehmen, in Zahlen fassen und – freilich in den Büchern nicht so genannt – dann mathematisch modellieren, im Prinzip live nicht nur lineare Trends anfitten, wie das das menschliche Gehirn tut, sondern eben weiter gehen, vieldimensionale, vielparametrige, nicht-lineare Modelle auf die als Zahlen wahrgenommene Realität anwenden, sie anpassen und als Prognose- und Handlungsempfehlungswerkzeug verwenden. Für den expansionistischen Rest des Konzils natürlich eine Eigenschaft, die sich hervorragend nutzen lässt, um langfristig überlegen zu planen.
Und so fühle ich mich manchmal, wenn ich die Welt in Zahlen, in als mathematische Funktionen gefassten Modellen erfasse, Modelle anpasse und das in Diagrammen darstelle, quasi wie eine Keloskerin unter den anderen Völkern. Klar, auch ich poste in den sozialen Medien und hier auf dem Blog sowas wie mein „Angeberbild“ vom Badenmarathon oder unterfüttere Erlebnisse mit (wenigen) Bildern von mir, der Landschaft oder anderen. Aber wenn ich mir zum Beispiel in die Mediathek der verwendeten Bilder der Highway Tales schaue, sind da weit mehr Diagramme als Fotos. Als Linien und Punkte gefasste Zahlen, eingeordnet zwischen Koordinatenachsen, unterschieden durch Farben und Markierungen, erläutert durch „Legenden“, also eine Beschriftung, welche Farbe für welchen Datensatz oder welches Modell steht. In welcher Hinsicht ich nun gegebenenfalls keloskerhaft plump bin, weiß ich nicht – in Sachen gymnastische Bewegung wahrscheinlich schon, aber langsam und träge zu Fuß wie eine Keloskerin bin ich nun nicht. Dennoch bin ich ein Nerd, arbeite mit Zahlen und Modellen und Diagrammen. Emotionsfrei bin ich nicht, alles andere als das. Schlechtes, Demotivierendes kann mich furchtbar runterziehen, Tolles unglaublich euphorisieren. Es ist auch nicht so, dass ich meinen Sport nur nach Zahlen betreibe – das Gefühl spielt eine große Rolle. Aber vieles erfasse ich in Zahlen, versuche, es in Modellen zu parametrisieren, Trends aufzuzeigen, Kenngrößen zu definieren und zu verfolgen.
Und ich werde – gefühlt – besser darin. Nachdem ich mir das PRAPP auf Höhenmeter zu rechnen begonnen habe, habe ich diesen Wert nun auch auf meine Läufe angewandt. Da ich ja immer noch ein bisschen mit Bildern im Hintergrund arbeite, habe ich… nun, einen Graphen etwas aufgehübscht:

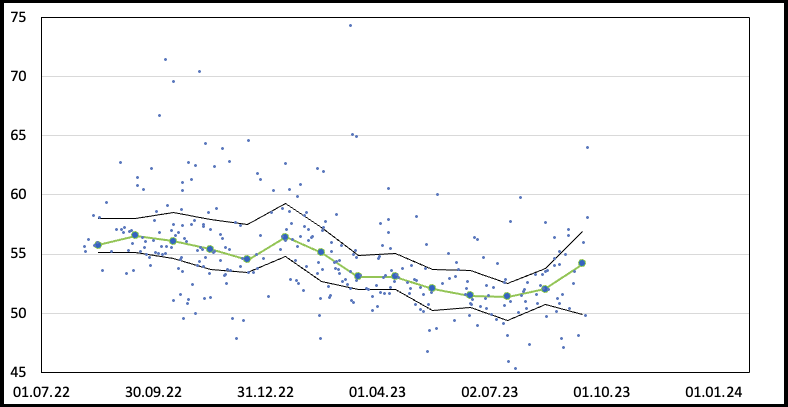
Im unteren, neuen Bild sieht man, dass tatsächlich auf Regensburg hin meine Formkurve anstieg, also das sbPRAPP im Mittel absank. Die grüne Linie mit blauen Markern stellt den Median des sbPRAPP im jeweiligen Monat dar, die schwarzen Linien 25- bzw. 75-Perzentile und die einzelnen Punkte sind die einzelnen Läufe. Offenbar hat meine Form nach Regensburg nochmal ordentlich zugelegt, nun beim abrufen von Leistung steigt der Wert an. Aber das ist bei harten Wettkämpfen nicht unnormal. Mal sehen, wie es sich weiter entwickelt.
Der Berg im Hintergrund des Graphen zur „Flachheit“ des sbPRAPP gegenüber den Höhenmetern ist übrigens der Nanga Parbat.
Weil ich so begeistert davon war, dass ich ohne numerischen Fit auskam, und so meine sbPRAPP-Funktion über eine analytische Lösung für eine Ausgleichsgerade automatisch angepasst wird, wenn neue Daten dazu kommen, habe ich für meine Wettkämpfe etwas Ähnliches gebaut.

In diesem Plot sieht man alle meine Wettkämpfe – die Distanz wird (logarithmisch) nach rechts aufgetragen, die „Pace“, also das Tempo in Minuten pro Kilometer nach oben. Blaue Punkte sind Wettkampfleistungen, die ich irgendwann gebracht habe, rot umrandete Rauten persönliche Bestleistungen auf der jeweiligen Distanz, grün hinterlegte Punkte oder Rauten sind „aktuell“, was im Moment bedeutet, dass die Leistungen nach dem 01.11.2022 erbracht wurden. Die rote Kurve ist ein numerischer Parabel-Fit an die Personal Bests, die gelbe Kurve ein Potenzgesetz nach Steffny und Riegel, basierend auf einer von Riegel 1977 aufgebrachten Formel. Demnach verhalten sich die Wettkampf-Zielzeiten zueinander wie die Wettkampfdistanzen hoch 1,07. Daraus folgt auch, dass sich das Renntempo wie die Wettkampfdistanz hoch 0,07 verhält… aber vielleicht ist ja der Exponent bei mir nicht 0,07, sondern 0,06, weil ich besonders gut auf langen Distanzen bin, oder 0,08, weil die ganz langen Distanzen mir bisher Probleme machen – Ihr ahnt es schon, es ist eher 0,08. Da steht dann also eine Funktion:
Wettkampftempo (x km) = Wettkampftempo (1 km) mal x hoch Exponent
Wenn ich das logarithmiere, ist es eine Gerade – und da kann man dann eine Ausgleichsgerade durchlegen, wofür es eine analytische Lösung gibt. Der Vorzug ist, dass sich bei neuen Personal Bests das Ganze automatisch aktualisiert. Wenn ich mich also irgendwann von der Parabel trennen kann, wird auch hier der Solver von Excel überflüssig, und somit aktualisiert sich meine ganz eigene Personal-Best-Funktion auf der Basis des Steffny-Riegel-Modells automatisch, wenn ich neue Personal Bests eingebe.
Dafür muss ich dann entweder endlich mein Potential im Marathon wirklich ausschöpfen – oder einsehen, dass ich bei der Parabel zwar eine schön kleine Summe der quadratischen Abweichungen erhalte, aber in erster Linie eben deswegen, weil ich „überfitte“, also nicht in der Natur der Sache, sondern in Schwankungen oder mangelnden Versuchen im Marathon liegende Strukturen mit in die Funktion nehme, was ich eigentlich nicht will.
Und dann brauche ich den Solver nicht mehr. Rede ich nun wie ein in die siebte Dimension sehendes Alien, das die Welt in Zahlen wahrnimmt?




